CHECK_RARE and making sense of unusual occurrences
Ray tracers are ‘interesting’ in that they end up doing a fairly similar set of computations—intersect, shade, sample, repeat—over billions of individual rays. (Apparently it was 13,486,203,269,559,350 rays to render Lego Batman—otherwise known as 13 million billion of them.) When rendering a scene, more or less the same code runs for each of those rays and accesses the same scene representation, just starting out with a different initial ray. Every once in a while, code that previously worked flawlessly for billions of rays before it will fail in a surprising way.
A fun example: a while ago at Google, someone was running a lot of jobs rendering with pbrt to generate some synthetic data. One of the jobs never finished; it turned out that the renderer was stuck in an infinite loop. I started digging in and found that it was stuck in a root-finding routine; this was surprising, since the algorithm used there had been carefully chosen to always make forward progress. It’d never been any trouble before.
That routine uses Newton-bisection to find the zero of a function. It maintains an interval that is known to bracket the zero and then works on refining the interval until it’s small enough. It first tries to take a Newton step, using the function’s derivative to estimate the position of the zero. If that leads to a point that’s inside the interval, it uses that as an improved interval endpoint. Otherwise it bisects the interval. This approach ensures that the interval gets smaller with each iteration.
How could that not terminate? It turned out that in that one run, pbrt came to a situation where the derivative at one endpoint of the interval took it exactly to the second endpoint and the derivative at the second endpoint took it exactly to the first. Here’s a sketch of what was going on (dashed lines represent the derivatives):
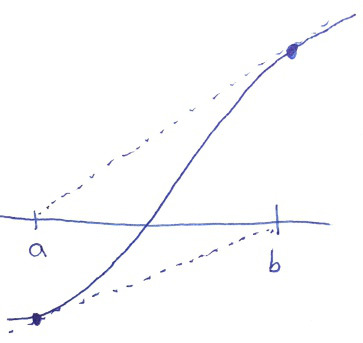
A rare state of affairs: we have a zero in the interval \([a,b]\), the derivative at \(a\) suggests that the zero is at exactly \(b\) and the derivative at \(b\) suggests it’s exactly at \(a\).
The problem was that given an interval \([a,b]\) and a proposed new \(t\) value from the Newton step, the check for whether to bisect instead was written like:
if (t < a || t > b) t = 0.5f * (a + b);
In this particular case, this code accepted the Newton step at each end and ended up endlessly jumping between the two endpoints. Good times. The fix was simple—bisect unless the new endpoint is strictly inside the interval:
if (t <= a || t >= b) t = 0.5f * (a + b);
When that check was first written, it was completely unimaginable that the interval and the derivatives would ever line in the way they did for that one run; what are the odds of that? But if you trace enough rays, then even these unimaginable things start happening now and again.
Assertions and rare occurrences
These sorts of rare-but-legitimate happenings can make it hard to write good assertions in a ray tracer; things that you’d like to say will never happen sometimes do, legitimately. That’s unfortunate, since assertions can be a big help when writing software; when they fail, a fundamental assumption has been violated, and you know something needs to be fixed. (John Regehr has a nice blog post on assertions that’s worth reading.)
Here’s an example of this challenge from a experimental branch of pbrt I’m
hacking around in: the following few lines of code call a Refract()
function that computes a refracted ray direction using Snell’s law. It
returns a Boolean value that indicates whether total internal reflection
has occurred.
Vector3f wo = ..., wi = ...;
Float eta = ...;
Normal3f n = ...;
bool tir = Refract(wo, n, eta, &wi);
As it turns out, this code is called after the Fresnel reflectance has been computed for the surface and is only called if some light has been found to be refracted as per the Fresnel equations. Thus, in principle, total internal reflection should never occur here: we’ve already implicitly tested for that case.
However, if we assert that tir is false, we’ll quickly find out that
theory and practice don’t always match up. The issue is that the math that
Refract() uses to check for whether total internal reflection has
happened is slightly different than the math in the Fresnel equations. As
such, rarely, they’ll come to inconsistent answers due to floating-point
round-off error.1 Therefore, we need to handle the total internal reflection
case here when it occurs:
if (tir)
return Spectrum(0);
That’s fine and easy enough, but it should make you nervous. What if,
contrary to our assumption, Refract() was actually returning false fairly
frequently? That’d mean there was a bug somewhere, but we just obscured it
by handling the total internal reflection case here.
Enter CHECK_RARE. Before handling the total internal reflection case,
there’s this line:
CHECK_RARE(1e-6, tir == true);
CHECK_RARE takes a maximum allowed frequency and a condition that
shouldn’t happen very often. During program execution, it tracks how
frequently the condition is true. Then, when the renderer exits, if the
condition was true too often—a statistically significant fraction of the
time more than the given frequency—an error is issued. At that
point, we know something’s fishy and can start digging in.
Implementation
The basic gist of what CHECK_RARE needs to do is to check the given
condition and tally up how many times it’s checked and how many times it’s
true. As a first doesn’t-actually-work whack at it, it’s just something
like this:
#define CHECK_RARE(freq, condition) \
do { \
static int64_t numTrue, total; \
++total; \
if (condition) ++numTrue; \
} while(0)
(Here’s what’s going on with the do
while(0), if that idiom isn’t
familiar.)
That obviously doesn’t work; not only will there be race conditions when we
run multi-threaded, there’s no way to check the accumulated counts at the
end of program execution. Here’s a full CHECK_RARE implementation that
handles that and more. It’s a little tricky, but we’ll discuss all the bits
of it below.
#define TO_STR(x) #x
#define EXPAND_AND_TO_STR(x) TO_STR(x)
#define CHECK_RARE(freq, condition) \
do { \
static_assert(std::is_floating_point<decltype(freq)>::value, \
"Expected float frequency as first argument"); \
static_assert(std::is_integral<decltype(condition)>::value, \
"Expected Boolean condition as second argument");\
\
static thread_local int64_t numTrue, total; \
\
using RareSums = std::map<std::string, \
std::pair<int64_t, int64_t>>; \
static StatRegisterer _([](RareSums &sums) { \
std::string title(__FILE__ " " EXPAND_AND_TO_STR(__LINE__) \
": CHECK_RARE failed: " #condition); \
sums[title].first += numTrue; \
sums[title].second += total; \
numTrue = total = 0; \
}); \
\
++total; \
if (condition) ++numTrue; \
} while(0)
First, the static_asserts: when I use CHECK_RARE I can never remember
what the order of parameters is, so those at least give useful compile-time
error messages when I get them wrong.
Next, the number of times the condition is checked and the number of times
it’s true are stored in thread_local variables. Naturally we’re running
multi-threaded here, and we don’t want to pay the cache-coherency cost of
using std::atomic variables for these counters; that’d be catastrophic
for performance. It’s much more efficient for each thread to keep its own
counts for now.
Then, there’s a funny little trick to be able to accumulate those
thread-local values when we want to sum them up at the end of program
execution: static StatRegisterer. Because it’s a static variable, the
StatRegisterer constructor will be run exactly one time, by whichever
thread gets there first. The StatRegisterer class just holds on to all
of the lambda functions its given; here’s its implementation in
pbrt-v3.
At the end of program execution, when we want to sum the counts, the thread
pool has a function that will run a given callback in each active
thread—it basically schedules a number of jobs equal to the number of
threads and includes a
barrier in the
jobs to ensure that each thread only runs one job. We set things up so
that each thread runs all of the lambdas provided to the StatRegisterer;
in turn, those add all of the thread’s local values to the global sums
stored in the RareSums map.
Whew.
What counts as failure?
Given the accumulated count of times that the condition was true and the
total number of times it was checked, the last thing is to decide if we’ve
found a statistically-significant result: for example, if an instance of
CHECK_RARE is called only once and the condition is true for that one
time, that doesn’t really tell us anything useful.
One way to formalize what’s going on here is as a Bernoulli process; we’ve got samples from an underlying process that can take on two conditions (true or false) with unknown probabilities. The maximum likelihood estimator \(\hat{\theta}\) of the probability of the condition being true is just the number of times the condition was true divided by the total number of samples, and the sample variance is \((\hat{\theta} (1 - \hat{\theta}))/(n-1)\).
These are easy enough to compute:
Float freqEstimate = double(numTrue) / double(total);
Float varianceEstimate = 1 / double(total - 1) * freqEstimate *
(1 - freqEstimate);
For a small expected frequency of an event and a large number of samples (the common case), this is basically the estimated frequency divided by the number of samples. It gets small quick.
I ended up deciding that two standard deviations was a reasonable
confidence level to require before reporting a failure. In practice, the
CHECK_RAREs in pbrt run frequently enough to have very low estimated
variance, so it’s not too fiddly about how many sigmas we require here.
if (freqEstimate - 2 * varianceEstimate >= maxFrequency) {
// report failure of CHECK_RARE....
}
And that’s it for CHECK_RARE; a pretty easy thing to implement in the
end. It’s nice to have in the toolbox; I’ve found that as I work through
pre-existing code that handles edge cases, it’s nice to leave a few
CHECK_RAREs behind, just to be sure it’s all working as expected.
They’ve found more than enough bugs along the way to be worth the little
trouble.
note
-
In a production system, the right thing to do here probably would be to refactor the code so that
Refract()used values previously computed for the Fresnel stuff, thus enforcing consistency. For pbrt, modularity is important as well, so this is what it is. ↩