The story of ispc: first users and modern CPUs coming through (part 6)
One thing that came out of volta’s impressive early results was an invitation to participate a series of parallel programming model bake-offs that were going on in the compiler team.
Here’s how it went: every few months, a group would be assembled with a
representative or two from each of Intel’s various parallel programming
efforts (TBB, #pragma simd, Cilk, OpenCL, and so forth). The process
would then take a few months, with everyone first agreeing on evaluation
methodology and then negotiating which workloads would be included. (And I
assure you that no one involved pushed for workloads that fit their model
well or tried to marginalize workloads that didn’t.) Performance was
measured, optimizers were tweaked, and in the end, we’d prepare a
presentation for the VP of the compiler group.
It was a feather in one’s cap to be a part of these, at least as far as a traditional Intel career went. My work is important enough to merit being presented to a VP sort of thing. It was something to be highlighted in one’s “brag sheet”, the self-assessment that one prepared every year for performance reviews. Some people worked on this document all year long, starting right after the last review cycle ended. There was no limit on length, and it wasn’t unheard of for them to be twenty pages long.1
In the end, the presentation would not just go through the performance results, but would also highlight the strengths of each programming model. Everyone got a trophy, and the bake-offs never seemed to affect Intel’s strategy.
I guess I was happy to be invited to the party, but I didn’t give these exercises a lot of my attention. I wasn’t interested in jealously guarding volta’s performance lead on these benchmarks as the implementers of the other models worked to close the gap; it was a lot more fun to start using it for more complex programs than the other models could handle and to start working with early adopters inside Intel.
Experiences with early users
Many of the graphics people at Intel were excited about and supportive of volta. Like I said, it was more or less the tool that many of them wanted.
A number of them had interesting graphics programs that they’d already implemented using intrinsics. This made for a great combination: we had well-written intrinsics implementations that volta’s results could be compared against, and we had smart programmers who knew what they wanted out of a compiler and weren’t afraid to read and critique assembly. The compiler was robust enough that other people started using it around December 2010.
One of the first users was Doug McNabb, who had written a particle rasterizer in intrinsics. He ported it to volta and… performance was terrible and the assembly was a mess. This result was initially a little terrifying to me—a total failure when faced with a new workload. Maybe this whole thing wasn’t going to work out as I’d hoped after all.
It turned out that he’d happened to use unsigned integers throughout his volta code, though not out of any particular need for them. And it turns out that there’s actually no SSE4 instruction that converts between vectors of floats and vectors of unsigned ints and thus, every time that had to happen (which was often), it got turned into a long chunk of scalar code, converting each vector element one by one.
I added a warning to the compiler about using unsigned ints with SSE4 and Doug made the quick fix to volta code to just use regular ints. Success! Clean assembly and performance within a few percent of his intrinsics code. Whew.
Another early user was Andrew Lauritzen, who had a clustered deferred shading workload that he was using to evaluate different ways of mapping that computation to parallel hardware—from Larrabee to GPUs. He had an intrinsics implementation and was happy to write a volta implementation, which is now one of ispc’s examples.

Deferred shading in ispc: 4.15x faster than scalar code using SSE4 on a single core and linear scaling over multiple cores.
Andrew’s deferred shading example was one of the longer volta programs written at the time, so once again, I was nervous. It was a relief that it worked well, pretty much right out of the box. I don’t have the performance numbers from then, but today it runs 4.15x faster with SSE4 (what we were testing with at the time) than with serial code on a single core, and scales pretty much linearly with the number of cores.
With Doug, Andrew, and other early adopters, it really helped that it was pretty easy to go from a serial C implementation to volta. First you put on your SPMD hat. Then you decide what to map SPMD program instances to—pixels, triangles, whatever the right thing was to loop over, and then that was about it. Most of your C code could be unchanged or only minimally updated.
This was, of course, the whole idea of SPMD on SIMD with a C-based language, but it surprised me how clean it was in practice. Compare, for example, the serial C++ implementation of a small ray tracer in the ispc examples to the ispc implementation; most of the code is pretty much the same.
Really, run those through your favorite graphical diff program; not that many lines are different, but the ispc exhibits performance that scales linearly over both number of CPU cores and SIMD width.
There were plenty of bugs found throughout the early adopters digging in, and I’m really thankful that they were generally unbothered by them, overall happy to contribute their time and insight to making this thing work better. Both their feedback and their enthusiasm was really helpful; it was great to become confident that like maybe this thing would work for problems they cared about, too.
Ode to modern CPUs
About that 4.15x speedup on Andrew’s deferred shading workload: that improvement was actually slightly better than the ideal 4x that SSE4 potentially offered. Sometimes that actually happened with volta; it was kind of spooky in a “am I measuring wrong?” sort of way. The deferred shading workload involves a few gathers and some divergent control flow; it isn’t perfectly regular, either.
This sort of result was particularly surprising in that until AVX-512, Intel’s vector ISAs weren’t at all designed with SPMD execution in mind. Until AVX they were particularly non-orthogonal and quirky (cf. converting between vectors of unsigned ints and floats in SSE4). One has the sense that they hadn’t been designed as something to use as a compiler target, but were rather a hodgepodge of operations that the architects had discovered were necessary to code up a few important kernels by hand.
When I first implemented SPMD control flow in volta, I had no idea how well
it would actually work in practice. I might have been able to correctly
run SPMD programs on CPU SIMD hardware, but if performance was terrible,
that wouldn’t have been very interesting. Divergent control flow was a
known risk: just like on a GPU, there’d be a penalty for divergent
execution: if some program instances take one branch of an if statement
and some take the other, then you’re unavoidably executing both sides,
running partially active for each one.
A more worrisome issue was that there were plenty of things that weren’t supported as vector instructions and had to be handled by breaking them down into the equivalent of a loop over the SIMD lanes, processing each one with scalar code. There were loads of these in the SSE4 days, and progressively fewer through AVX, AVX2, and AVX-512.
As an example, here’s a short volta/ispc function that does a scatter: the
value of index is unique per SPMD program instance; thus, each instance
generally writes to a completely different (and potentially non-contiguous) memory
location:2
void scatter(uniform float ptr[], int index, float val) {
ptr[index] = val;
}
With modern AVX-512, things are lovely and there’s a native scatter
instruction vscatterdps that can completely take care of this. With
everything before AVX-512, it was necessary to generate code that
basically loops over the vector lanes, tests to see if the execution mask
is enabled for each one, and then writes the lane’s value to memory only if
so.
It ends up being 23 instructions total for SSE4; more for AVX, where there are twice as many vector lanes. Here’s the start of what’s generated for SSE4, covering where the first vector lane is handled:
movmskps %xmm2, %eax
testb $1, %al
je LBB0_2
movd %xmm0, %ecx
movslq %ecx, %rcx
movss %xmm1, (%rdi,%rcx)
LBB0_2:
testb and je jump to the next lane if the current one isn’t active, and
those three moves line things up and write to memory if it is. Then, more
or less the same thing, three more times. In addition to all of the
instructions, it’s short sequences of instructions with
not-necessarily-very-predictable branches; also not great news for
performance.
So what was going on with that deferred shading workload and the others that had the occasional gather or scatter or the like but still ran efficiently? The best answer I could come up with was that out of order execution hides a multitude of sins.
Intel CPUs are at really good at running terrible code. That’s a funny thing to write, but I mean that as a high compliment; I think it’s one of their real competitive advantages. It’s easier to build a processor that runs perfect and regular code highly efficiently than it is to build one that runs whatever crap is thrown at it decently well—virtual function calls, cache-unfriendly code, branchy code, etc. I think one of Intel’s great talents has been to deliver on running all that stuff well—much better than the competition.
Another example of an even more challenging workload: the ispc distribution has a small volume renderer. (Again, the ispc implementation looks very much like the C++ one.) It generates this image:
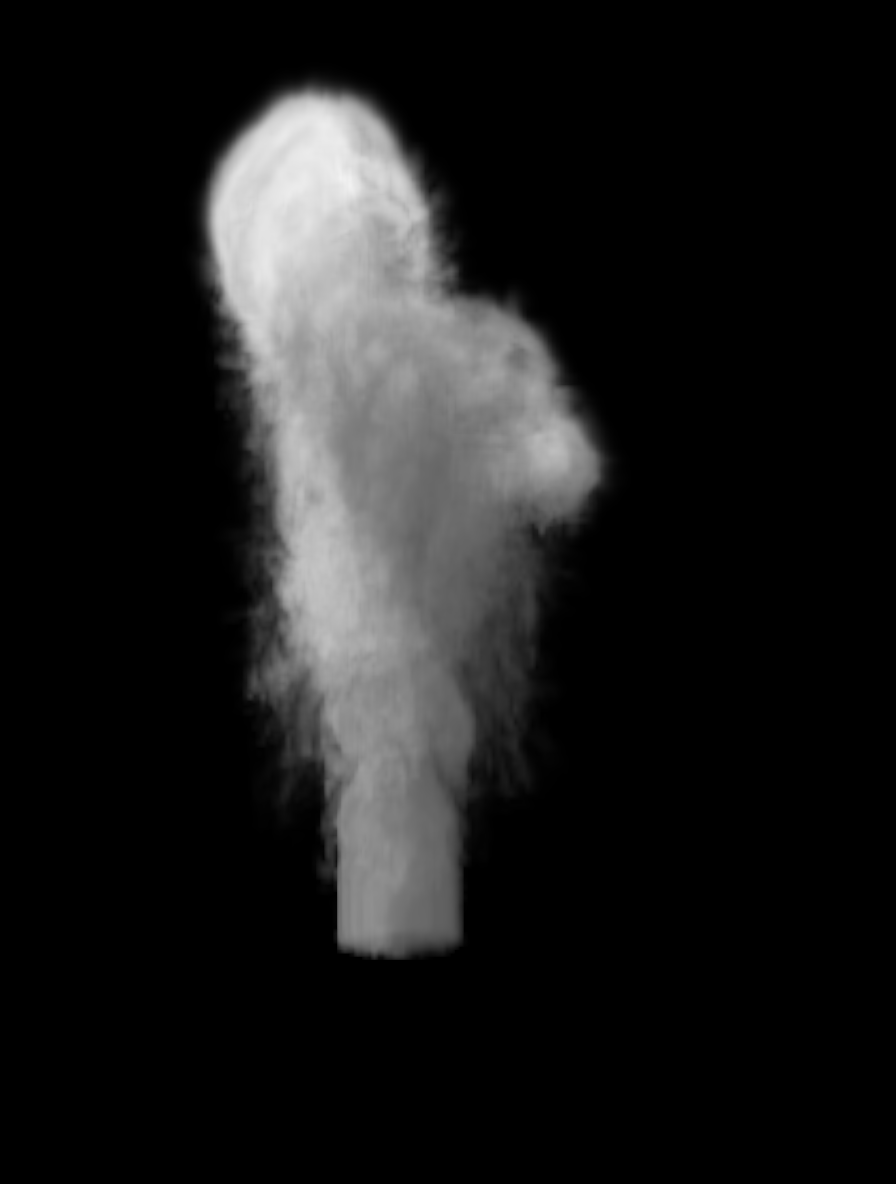
When I first wrote it, I had no idea if it would actually run faster in volta than in scalar code; it’s not very SIMD friendly at all. The main kernel of the computation steps rays through a regular grid of volume density values and trilinearly interpolates the 8 neighbors to compute a density and computes lighting at each point. Thus, it requires 8 gathers at each point along each ray, as each vector lane potentially reads different memory locations to get its density value.
It continues stepping forward into the volume until the opacity is high enough that lighting from further points along the ray won’t make a difference. Thus, there’s also irregular control flow: in a group of rays running across SIMD lanes, it has to keep going until all of them have decided to terminate.
On a 2 core laptop running the SSE4 version (the target that I first tested it with), the ispc implementation is 5.2x faster than serial code. Note that this is only 65% of the speedup one might hope for in the best case—2x from multi-threading and 4x from 4-wide SSE, or 8x total. Using AVX2 on the same 2 core system, the ispc version 7.7x is faster than serial code. Better overall, but just 48% of the ideal. Presumably the native gather instruction in AVX2 helps some, though the efficiency cost of divergent control flow is higher, now running 8-wide.
In any case, I think that performance is surprisingly good: I half-expected that workload to see no benefit at all from mapping it to SIMD hardware; that sort of speedup for something that’s that irregular is something I can be quite happy with.
Next time, we’ll cover experiences bringing up the AVX backend and interactions with the LLVM team.
Next: Bringing up AVX and giving something back to LLVM